On UUID Performance in Postgres
Posted by Viacheslav Andzhich in Uncategorized on February 4, 2024
Jeremy Schneider’s excellent research on the topic of UUID and underlying data types really came in handy when i’ve started to research possibilities to switch to UUIDs in one of the projects
PS: aside from a lots o f good information on the topic, Jeremy also shows some valuable approaches to testing and benchmarking of database performance with spectacular and easily readable graphs as results. Clearly a must read post, as well as the whole blog, I figure 🙂
Reading MS Excel Files through External Tables
Posted by Viacheslav Andzhich in Oracle on October 14, 2019
Lately I had a customer, who needed to load xlsx files into the database on regular basis.
Unlike csv or other text format xlsx is a proprietary binary format, that Oracle seem to be reluctant to support at least until lately. So, you can’t just read an Excel file through an external table using native Oracle drivers, unless you can install APEX 19.1+. There are also other solutions using data cartridge, java and pl/sql. But both options were overkill for me, especially getting DBAs to install APEX, which was considered a system level change and needed to undergo a lot of approvals and paperwork.
Suddenly I recalled, that we have Python installed on almost all servers in the network, since it’s widely used across the organisation. Then, what if I write a Python script that takes xlsx files and yields plain text, and use it as preprocessor in external table? That should be elegant and simple enough, and also seem to conform to the organisation’s security requirements.
Preprocessor is an embedded feature of Oracle that lets you run an OS level executable against data files before reading them into the database. For example, if you have a compressed file, you could run GZIP or UNZIP command as preprocessor to get uncompressed version right in the moment of querying your external table. The limitation here is that the preprocessor must return result to stdout, and accept only one input argument, that is the file name to be processed. If you need more arguments for your preprocessor, then you could just wrap the whole thing in a shell script, and specify additional arguments inside.
Now we need a Python script that would perform conversion for us. At this point we might start digging into xlsx specification details, write some simple snippets to prove the concept etc. Or, would it be wise to recall, that Python has a huge library of everything, from simple math tools to AI scripts, already implemented for you? And in our case, googling “Python xlsx to csv” quickly gets us a very neat tool xlsx2csv. Small and simple Python script with some advanced capabilities to convert documents with multiple sheets, adjust encodings, data formats, quotes, delimiters and a lot more. It’s a very simple installation using PIP:
pip install xlsx2csv
And now we can try it out right from our shell:
xlsx2csv input_file.xlsx output_file.csv
For the next example I exported standard EMP table as an xlsx file. Now let’s see what happens if we specify it as the only argument for the script (pretty much what Oracle would do when it’s involved as a preprocessor):
[oracle@ora122 ~]$ xlsx2csv emp.xlsx
emp,,,,,,,
EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO
7369,SMITH,CLERK,7902,17.12.80,800,,20
7499,ALLEN,SALESMAN,7698,20.02.81,1600,300,30
7521,WARD,SALESMAN,7698,22.02.81,1250,500,30
7566,JONES,MANAGER,7839,02.04.81,2975,,20
...
I cut the output slightly to save space, but already we can see that it does exactly what we need: produces csv data as standard output. Now it shouldn’t be harder than that to specify the preprocessor clause for the external table:
preprocessor preprocessor_dir:'xlsx2csv'
But we need to take a closer look at the first two lines of the output: the second one represents column names, but the first one looks like a table/file name in the first cell with all other cells empty (’emp,,,,,,,’). Is that a part of original file or a feature of xlsx2csv? Let’s take a look at the xlsx file first:
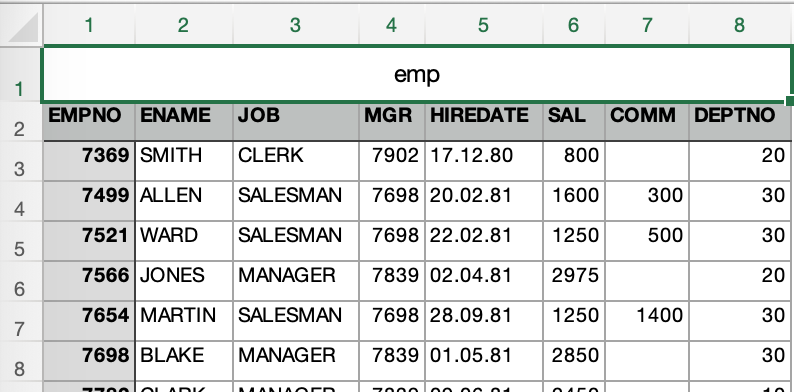
Ok, found the culprit at the first try. It’s an export glitch. But for our case, let’s assume that we always get the file with this heading , and we need to process it correctly. So, we basically need to skip first two lines to get to the actual data. Xlsx2csv won’t provide us with a parameter to skip lines, though it’s fully open sourced, so we could review the code, and add the parameter. But it seems like a wasted effort, given that Oracle allows us to skip lines with a single option of external table access parameters (skip n), so let’s stick with it.
Now to the actual implementation. To get the external table working we need a preprocessor to be copied in the special Oracle directory, where you have EXECUTE privilege. Defining /usr/bin as such is probably a very bad idea. Putting the script into the same directory where your data resides is not ideal as well. Oracle recommends to create a dedicated directory for preprocessors, and carefully control who has access to it. Let us follow the recommendation (connected to 12.2 db as andzhi4):
SQL> create directory preprocessor_dir as '/home/oracle/preprocessor';
Directory PREPROCESSOR_DIR created.
Now we need our xlsx2csv script copied into that directory:
[oracle@ora122 ~]$ pwd
/home/oracle
[oracle@ora122 ~]$ mkdir preprocessor
[oracle@ora122 ~]$ which xlsx2csv
/usr/bin/xlsx2csv
[oracle@ora122 ~]$ cp /usr/bin/xlsx2csv preprocessor/
Assume we already have xlsx file in our data directory (my_data), we could start creating the external table:
create table "ANDZHI4"."EX_EMP" (
"EMPNO" number(4, 0) not null enable,
"ENAME" varchar2(10 byte),
"JOB" varchar2(9 byte),
"MGR" number(4, 0),
"HIREDATE" date,
"SAL" number(7, 2),
"COMM" number(7, 2),
"DEPTNO" number(2, 0)
)
organization EXTERNAL ( type oracle_loader
default directory "MY_DATA"
access parameters (
records skip 2
BADFILE 'emp_%p.bad'
noDISCARDFILE
LOGFILE 'emp_%p.log'
preprocessor PREPROCESSOR_DIR:'xlsx2csv'
FIELDS TERMINATED BY "," OPTIONALLY ENCLOSED BY '"' LDRTRIM
ALL FIELDS OVERRIDE
MISSING FIELD VALUES ARE NULL
REJECT ROWS WITH ALL NULL FIELDS
(hiredate date 'DD.MM.RR' )
)
location('emp.xlsx') );
That’s my regular external table template to load csv data, but modified to use preprocessor script. Note that we use ‘Records skip 2’ option in access parameters to reject first two lines of the file. Also, we don’t parse HIREDATE column on the Python level, but do it in table definition as column override (hiredate date ‘DD.MM.RR’ ) . The year is stored as 2 digits, thus we need to use RR in format mask to correctly represent years from the past century (YY would give us 2081 for 81).
And that’s pretty much it, now you have a way to put your xlsx file right in the folder accessible by your database server, and read data directly from there. This approach works fine for multiple data files and for wild characters in names. Oracle will run preprocessor for every file identified. Parallel execution is also supported, though the parallel degree is limited to the number of data files you have in your directory.
Also, pay attention to some restrictions Oracle possess for preprocessor use:
- The
PREPROCESSORclause is not available on databases that use the Oracle Database Vault feature. - The
PREPROCESSORclause does not work in conjunction with theCOLUMNTRANSFORMSclause.
I didn’t hav any of this in my recent deployment, though database vault might get in your way relatively often. Also, be aware that granting execute privilege on any Oracle directory means that database user can run custom OS level code, what might represent sensible security risk. Careful reader might have noticed that we never provided execute privilege on preprocessor_dir in this post. That’s because I run my examples as a user with DBA role (though for last releases Oracle warns “This role may not be created automatically by future releases of Oracle Database”, it still works in 12.2 ):
SQL> select granted_role from dba_role_privs where grantee = user;
GRANTED_ROLE
DBA
CONNECT
This means, I can create directories, and thus I have all privileges on them by default:
SQL> select grantee, privilege from dba_tab_privs where table_name = 'PREPROCESSOR_DIR';
GRANTEE PRIVILEGE
ANDZHI4 EXECUTE
ANDZHI4 READ
ANDZHI4 WRITE
Of course, this is not the case for production roll out, where you as a developer need to request explicit grant on appropriate directories from DBA.
Now that’s all I have for you today. Take care )
Oracle 12.2 sort-merge + filter bug
Posted by Viacheslav Andzhich in Uncategorized on October 5, 2017
To cut the long story short and to avoid messing with awful wordpress formatting tool, I would like to give you here a brief description of the bug I’ve hit a couple of weeks ago in Oracle Database 12.2. The full investigation and scripts are attached here as downloadable files.
The problem appeared when we’ve been running a query with left join written in ANSI syntax:
SELECT 1
FROM (
SELECT
e.enterprise_id eeid,
m.enterprise_id meid
FROM Enterprisedata e
LEFT JOIN merchant m ON m.merchant_id = -11)
WHERE coalesce(meid, 1) = eeid;
In test setup we have three rows in enterprisedata and one row in merchant , there are no rows with m.merchant_id = -11. So we expect the subquery to return from join all the rows from enterprisedata and null values for m.enterprise_id:
| EEID | MEID |
| 1 | null |
| 2 | null |
| 3 | null |
Then we apply filter WHERE coalesce(meid, 1) = eeid, so we suppose only first row to survive, so the main query would return one row with “1” in it.
And it works Ok in 11.2 and 12.1, except that 11.2 uses sort-merge join in execution plan and 12.1 always chooses NL (it doesn’t even consider SM when we look into 10053 trace). And that’s where the story begins – users started to complain about poor peformance of NL join in 12.1, and Oracle released fix 22258300 to address this. It’s fact that after fix is enabled you get sort-merge for left joins, but at the same time the query shown above started to return no rows at all. And the join itself still produced the expected output, but it was FILTER operation in the execution plan that swallowed the row we expected to be returned.
Issuing alter session set “_fix_control” = ‘22258300:OFF’; immediately returns NL and the query starts to produce correct result.
Details of investigation are in the word document.
All additional scripts and reports are in the zip archive.
PS: Need more fun? The try to issue the original query with /*+rule*/ hint 🙂
Take care.
DBMS_FGA.all_columns
Posted by Viacheslav Andzhich in Uncategorized on September 8, 2017
While defining fine grade audit policies on your tables, you can have a desire to reduce the amount of data written to the audit log by using audit_column_opts parameter of the DBMS_FGA.add_policy procedure. It seems reasonable not to log queries to a table if the query won’t reveal a sensitive information. Let’s take a shopworn EMPLOYEES table as an example. Assume, you need to log any query to the table that returns employees’ salary information. It’s obvious that to get a useful data you need both employee name (or ID) and the salary, each of the values by itself is useless – not much profit in selecting only names or only salaries. So, to optimize your audit records you decide to log access to both these columns only by defining an FGA policy like that:
BEGIN
dbms_fga.add_policy(
object_schema => 'TESTUSER',
object_name => 'EMPLOYEES',
policy_name => 'emp_policy',
audit_column => 'SALARY, EMP_NAME',
audit_column_opts => dbms_fga.all_columns
);
END;
This example was given by Steven Feuerstein in his book “PL/SQL for Professionals.” At a first glance it makes sense – no one is able to get access to the confidential data without being caught by the FGA, and meaningless queries like
select salary from employees;
are not logged. And when somebody tries to get access to both of the columns, you see it in the audit trail:
SELECT
name,
salary
FROM employees;
...
select * from dba_fga_audit_trail;
SSSSION_ID,TIMESTAMP...
1790065,2017-09-08 18:55:03...
1790065,2017-09-08 18:58:30...
So, can we get a cup of coffee and relax now? Probably not so fast – nobody stops me from issuing these two queries:
SELECT emp_name FROM employees order by rowid;
SELECT salary FROM employees order by rowid;
Neither of them is caught by our FGA policy, but user can combine both results row-by-row in excel, reconstructing the original data. Not a result we wanted, ha?
In these case I would suggest to switch to the default:
audit_column_opts => dbms_fga.any_columns /*or exclude this parameter at all*/
And sacrifice a bit of disk space for more reliable auditing.
Take care.
Write consistency and before triggers
Posted by Viacheslav Andzhich in Oracle on August 28, 2015
Oracle database has just brilliant implementation of read consistency through the multiversioning. I.e. when you querying data, your query will not be locked and you will get correct answer from the database without blocking any other reading or writing transactions. Actually, there’re two particular cases when your reading request can be blocked, but we’ll talk about it sometime later.
So what about the write consistency? If I want to know a balance of some account I just issue a SELECT statement, say at time T1, and while my transaction is looking for the required row, let’s imagine, the value of the balance is changed by a concurrent process at time T2. What should I do now? Because of Oracle uses CONSISTENT GETS to query the data in the time consistent state, it founds that SCN of the data block has changed, and the block image should be reconstructed from the undo segment. That’s the very simplified model of Oracle’s read consistency. But what if we want not only to read the block, but also to update the value? Let’s say I want to do something like:
update t1 set balance = balance + 100 where balance > 400;
What should I do when I found that consistent version of the block differs from the current one, i.e. the row satisfied my predicate at the start time of the transaction but became inappropriate when I actually reached it, say, somebody managed to change the balance from 500 to 300. Of course I’m not eligible to update this row since it’s out of my predicate. But Oracle have been using consistent gets to find the appropriate rows, it means in terms of multiversioning read consistency the row is still has the old values of 500. How can we now find out that update must not be performed. The answer is: we need to query the CURRENT version of the block (it displayed as DB Block Gets in the sqlplus statistics) and compare the new value with the old one. Let’s consider a simple example:
SQL> set autotrace trace stat
SQL> select * from t1 where id <= 10;
10 rows selected.
Statistics
----------------------------------------------------------
8 recursive calls
0 db block gets
9 consistent gets
0 physical reads
0 redo size
1319 bytes sent via SQL*Net to client
551 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
10 rows processed
SQL> update t1 set n_1000 = n_1000*10 where id <= 10;
10 rows updated.
Statistics
----------------------------------------------------------
0 recursive calls
21 db block gets
2 consistent gets
0 physical reads
0 redo size
861 bytes sent via SQL*Net to client
855 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
10 rows processed
We can see that while reading the table contents Oracle doesn’t perform current reads at all (0 db block gets), but when we update the table using the same predicate it needs to check whether the current version of block differs from the consistent one (21 db block gets).
What will happen if the block has changed and we are not eligible to update it anymore? In that case Oracle rollbacks all the changes made by the update statement (or other DML) and restarts the operation, but for this time it uses SELECT FOR UPDATE mode to lock all the rows that we want to update. Notice that Oracle doesn’t rollback all the transaction but only the DML statement that faced the current version change problem. Also important thing – if we use the SERIALIZABLE isolation level of the transaction, then in this point we get “ORA-08177: can’t serialize access for this transaction.”
Ok, and what next? The most interesting side effect of such behavior of the DML statements connected with BEFORE FOR EACH ROW triggers. The before trigger fires (surprise!) before the actual data modification in the block and consequently it is capable of rewriting the :NEW pseudo record values. In practice it means that this type of triggers will fire twice if a DML has to restart. How can we prove it? Let’s just implement on practice all the above principles. Assume that we have a table named T_BEFORE_TEST defined like this:
SQL> describe T_BEFORE_TEST;
Name Null? Type
----------------------------------------- -------- ----------
X NUMBER(38)
Y NUMBER(38)
Let’s create a before trigger on it:
CREATE OR REPLACE TRIGGER tbt_bu_trg
before update on t_before_test
for each row
begin
dbms_output.put_line('Old X = '||:old.x||', Old Y = '||:old.y);
dbms_output.put_line('New X = '||:new.x||', New Y = '||:new.y);
end;
/
So, it just reads and displays the values of :new and :old pseudo records. This example was provided by Tom Kyte in his book Expert Oracle Database Architecture.
Let’s now populate the table with some data:
insert into t_before_test values (1,1); commit;
In the first session we will now start the update operation:
update t_before_test set x = x + 1 where x = 1;
It updates one row and holds the exclusive lock on it since we have not terminated the transaction. In the second session I would like to issue an update statement (and set serveroutput on to see the trigger’s output):
SQL> set serveroutput on
SQL> update t_before_test set x = x + 1 where x > 0;
Notice, that modifications made by first session will not remove the record for the predicate scope. This transaction now waits for the our first session to release the lock; so we returning back to the first session and commit the transaction. Now let’s see what happened in the second (locked) session:
SQL> update t_before_test set x = x + 1 where x > 0;
Old X = 1, Old Y = 1
New X = 2, New Y = 1
Old X = 2, Old Y = 1
New X = 3, New Y = 1
1 row updated.
It’s interesting! We see that trigger fires twice: first time when Oracle performed the consistent get and the second when it restarted the update due to differences between consistent and current version of the block.
Let’s dive deeper and modify the query in the second session like this, while the query in the first one left the same (I’ve truncated the table and reinserted initial values (1,1)):
update t_before_test set x = x + 1 where y > 0;
Now in the predicate we’re using the field that isn’t even modified by the first transaction; it means that the current version of the field and the consistent one are equal. Should we now assume that Oracle will not restart the operation and trigger will fire only once? No :), we still see the same output:
SQL> update t_before_test set x = x + 1 where y > 0;
Old X = 1, Old Y = 1
New X = 2, New Y = 1
Old X = 2, Old Y = 1
New X = 3, New Y = 1
1 row updated.
But why? It looks completely illogical. The reason of such behavior is hidden in our before trigger. Well, as we can see, it’s enough for Oracle that we only referencing new and old values in the trigger body to admit the current version of data can be different. Let’s just replace the references to :new and :old with static text and recompile the trigger:
CREATE OR REPLACE TRIGGER tbt_bu_trg
before update on t_before_test
for each row
begin
dbms_output.put_line('Trigger tbt_bu_trg fired');
end;
/
Now we should repeat all the operations we’ve done before (the table is reverted to the initial values again). In the first session:
update t_before_test set x = x + 1 where x = 1;
In the second:
update t_before_test set x = x + 1 where y > 0;
Now we’re commiting the changes in the first session and looking on the output of the second:
SQL> update t_before_test set x = x + 1 where y > 0;
Trigger tbt_bu_trg fired
1 row updated.
We can clearly see that triggers fired only once.
This side effect can be easily left unnoticed if you don’t understand how Oracle performs consistent writes. It’s especially unpleasant when the trigger performs some operations that are not the part of the original transaction, e.g. email sending, file IOs, or simply autonomous transaction operations. The statement level before triggers or all types of after triggers not susceptible to this effect.
The bottom line is: you should be really careful while implementing before for each row triggers, without appropriate level of understanding the architecture features of the Oracle database they can bring a lot of problems.
Remote DDL and transaction integrity
Posted by Viacheslav Andzhich in Oracle on August 18, 2015
Well known fact that DDL operations trigger the commit of the transaction. E.g. if you’ re issuing the following statements:
update t1 set sum = sum + 100 where id = 1;
create user testuser identified by password;
Then your transaction gets commited regardless of the result of the “create user” statement. Yeah, actually, the above is the example of how not to write pl/sql code, though some real world applications have the simillar problem hidden deeper than you might expect.
The most intresting thing here is that the local transaction will behave the same if it involves DDL on a remote database through a dblink. Let’s assume we have the procedure on a remote server that creates a user with the name passed through the parameter P_USER. For simplicity we will assign a static password to the user. Though in a real system password must not be stored as plain text of course:
create or replace procedure cuser (P_USER in varchar2)
as
begin
execute immediate 'create user '||P_USER||' identified by password';
end;
This is just a test procedure, not a real production code.
Now let’s get back to our local instatnce and create a dblink to be eligible to call the procedure above:
CREATE DATABASE LINK OL7_LOCALDB
CONNECT TO ANDZHI4
IDENTIFIED BY password
USING 'OL7.LOCAL:1521/LOCALDB';
Of course if you’d like to test it on your machine you should use appropriate hostname, schema and password.
Commonly there no other users in my test environment and V$TRANSACTION view has no rows:
SQL> select addr from v$transaction;
no rows selected
SQL> select v1 from t1 where id=2;
V1
------
2
Now let’s start a new transaction by issuing the following statement:
SQL> update t1 set v1 = v1+10 where id=2;
1 row updated.
SQL> select addr from v$transaction;
ADDR
----------------
00007FFB6F5E9088
Now we see active transaction. Let’s call our remote procedure that will create a user on the remote instance:
SQL> begin
2 cuser@ol7_localdb('testuser1');
3 end;
4 /
PL/SQL procedure successfully completed.
SQL> select addr from v$transaction;
no rows selected
SQL> select v1 from t1 where id=2;
V1
------
12
We can see that the remote procedure has commited our transaction. Moreover, if we repeat these steps, we will get the same result again regardless of the fact that the procedure now return the error:
ERROR at line 1:
ORA-01920: user name ‘TESTUSER1’ conflicts with another user or role name
ORA-06512: at “ANDZHI4.CUSER”, line 5
ORA-06512: at line 2
SQL> select v1 from t1 where id=2;
V1
------
22
Even more interesting thing – this problem used to appear on a real production system. The system was intended to create user policies for their access to the applications. Some of the requests involve creation of the user on the remote database. There were issues with transactions integrity – due to commit in the middle of the process some changes was not possible to rollback in case of failure, and it led to chaos in the database.
I’ve found three workarounds for this problem: one of them is to issue the remote call as the first statement of your transaction, this will minimize the number of irrevocable changes, but it can be used only as a simple temporary solution. More advanced and reliable method is to wrap all remote procedure calls in the local procedures with PRAGMA AUTONOMOUS_TRANSACTION so that DDL statement will not be able to commit any local changes. Here is the simple example:
create or replace procedure remote_cuser (P_user in varchar2, rest out number)
as
pragma autonomous_transaction;
begin
cuser@ol7_localdb(P_user);
rest := 0; --success
exception
when others then
rest := 1;
end;
And anonymous block that implements the logic of the first example but without unhandled commit:
declare
l_res integer := 1;
begin
update t1 set v1 = v1 + 100 where id = 1;
remote_cuser ('tstusr12', l_res);
if l_res = 0 then
commit;
else
rollback;
end if;
exception
when others then
rollback;
raise;
end;
And the third solution is to use DBMS_SCHEDULER to perform a task on the remote system. This way the ddl will be executed by the job process and will not affect our transaction at all.
Thank you for your attention and good luck.
Oracle Bitmap Indexes Restrictions
Posted by Viacheslav Andzhich in Oracle on July 23, 2015
There is one intresting thing in the Oracle documentation on bitmap indexes, you can find it here:
http://docs.oracle.com/database/121/DWHSG/schemas.htm#CIHEAGDC
It says:
- The columns in the index must all be columns of the dimension tables.
Though you can perform a simple test (I’ve done it in 12C, but I believe it’s true for 11G also):
CREATE TABLE tst_date_d
(
date_id INTEGER NOT NULL PRIMARY KEY,
calendar_date DATE NOT NULL UNIQUE,
calendar_year INTEGER NOT NULL
);
CREATE TABLE tst_sales_fact
(
transaction_date_id INTEGER NOT NULL REFERENCES tst_date_d (date_id),
quantity NUMBER NOT NULL,
total_value NUMBER NOT NULL
);
CREATE BITMAP INDEX tst_sf_trans_date_idx
ON tst_sales_fact (d.calendar_date, s.quantity)
FROM tst_sales_fact s, tst_date_d d
WHERE d.date_id = s.transaction_date_id;
This code completes without an error.

Recent Comments